| Soft clustering |
|
|
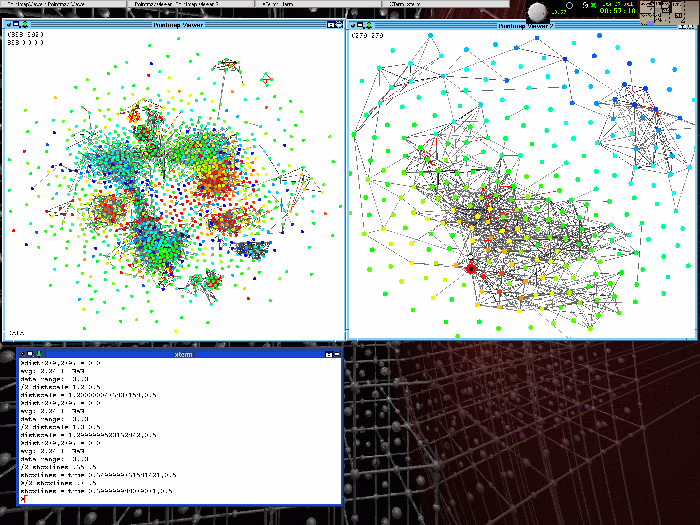
Clustering gene expression data involves identifying genes that have similar expression patterns over a variety of experiments. Traditionally, such clustering assigns a discrete cluster label to each gene. We are investigating clustering methods based on multidimensional scaling. In this method, genes are assigned coordinates in a low-dimensional space in such a way that genes with similar expression patterns are assigned places close to each other. Applied in two dimensions, this creates a planar map in which clusters can be visually identified and relations between clusters investigated interactively. By using this method both to map genes and experiments, we are looking for characteristic patterns in gene expression data that can serve as input to network inference applications. We use a numerical method using different distance kernels to obtain a map that represents a chosen correlation measure between genetic expression profiles. By choosing different correlations measures, data subsets, and distance kernels, we can focus on different aspects of the data. The optimization of the map is done either using a gradient-descent algorithm or with a hybrid molecular dynamics Monte Carlo algorithm. To avoid jamming, the minimization takes first place in a higher-dimensional space, which is then reduced by applying an external field to the data points. Once the data is mapped to the plane, we employ supervised-learning approaches to describe to properties of the mapping. The optimization process of the mapping is a self-organization process in which the algorithm identifies a set of features in the data that can be well represented in the plane. This features set can be extracted by considering the information entropy of the map, rule-based location assignment of the points, and local prototypes. →Presentations and publications
|
|||||||||||||||
|
|||||||||||||||